Digital Audio 101: The Basics
08/23/2021
Article Content
What Is a Sound Wave?
Before talking about the digitization of sound it is crucial to understand what a sound wave is exactly. Sound waves are realized when an instigating factor, such as the striking of a drum head or the plucking of a string, causes the molecules of a medium, typically air, to move. The molecules vibrate in a process that alternates between compression (becoming denser and tightly packed) and rarefaction (becoming less dense). The wave propagates in this way through the medium until its energy is dissipated in the form of heat. It should be noted that the medium could also be a liquid or a solid, and in fact, air is one of the slowest mediums for transmitting sound. The diagram below identifies how the amplitude of a sine wave would correspond to the compression and rarefaction of molecules in a medium.
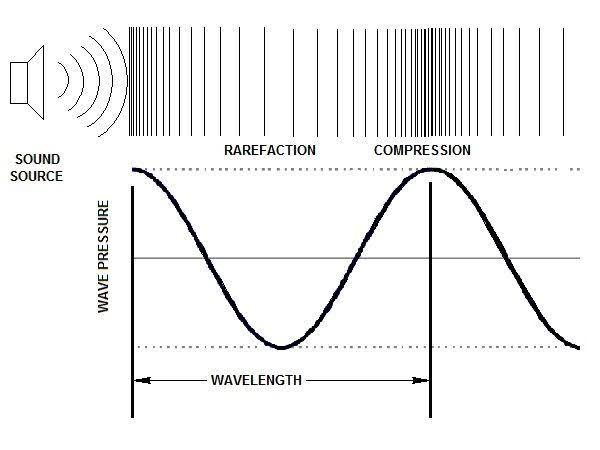
(source)
Anything that vibrates — a string, drum head, wine glass, tuning fork — will produce a corresponding movement of molecules in the medium which we perceive as sound.
What Is Analog Sound?
For some people, the term analog sound refers to old technology — which is of course true to some extent. But analog technologies remain a crucial part of music production. To understand why, we should define the origin of the term. The word “analog” is derived from the word “analogous” which means comparable, similar or related. In terms of audio technology, this idea is clearly present in two fundamental devices for recording and creating music — the speaker and the microphone.
Microphones create a change in voltage or capacitance that is analogous to the movement of its diaphragm, which is instigated by a sound wave.
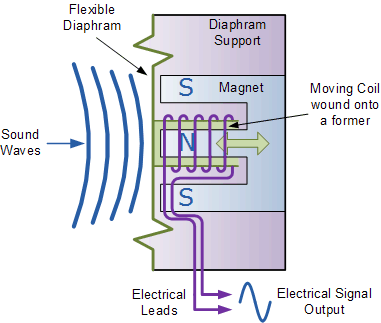
(source)
Speakers transform an electrical signal into a sound wave by creating analogous movements of a speaker cone.
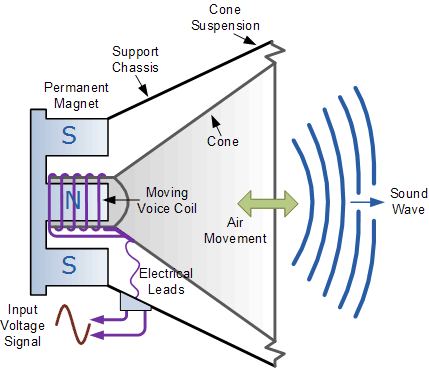
(source)
Both devices are considered transducers, in that they convert one form of energy into another. And both are analog devices that are just as relevant today as the day they were invented.
How Is Sound Digitized?
Before the advent of computers, sound was recorded using technologies like magnetic tape, vinyl and — very early on — wax cylinders. Engineers strived for the highest fidelity possible depending on the limitations of the medium. One of the major potential limitations is that of dynamic range — the range of possible amplitude values from the noise floor to the maximum peak level before the onset of distortion. As audio production technology has advanced, so has dynamic range as evidenced below:
Approximate Dynamic Ranges
FM Radio: 50 dB
Cassette Tape: 60-70 dB
Vinyl: 70-88 dB
Audio CD: 96 dB
24 Bit Audio: 144 dB
It should be noted that the goal of absolute fidelity is a bit of a misnomer. The resurgence of vinyl and retro or lo-fi aesthetics indicates that taste and the effect or “limitations” of a particular medium can be valued as part of the process and the so-called flaws in audio fidelity might be actually desired.
The digitization of sound is necessary whenever computers are involved in the recording, production or dissemination of music, which pretty much covers everything except live performance. And even then, on-stage musicians are probably using digital effects somewhere along the line.
To convert analog sound to the digital realm means taking an analog signal and creating a representation of that signal in the language of computers, which is binary (zeroes and ones). Check out my article for detailed information on binary systems and audio: “Bits, Bytes, and Beers.”
An analog signal is continuous, meaning constantly changing in amplitude and time. Digital conversion requires that it be sampled or measured periodically to make it understandable and editable in a computer system. There are two conversion-related terms to be aware of:
Analog to digital converter (ADC) – converts an analog signal to a digital file
Digital to analog converter (DAC) – converts a digital file to an analog signal
This pairing of devices or processes is the essence of digital audio production.
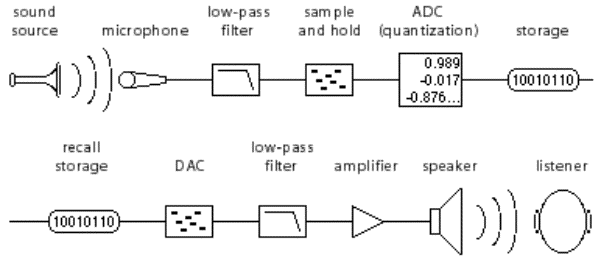
(source)
Sample Rate and Bit Depth
The digitization process has several user-defined variables which will influence things like frequency range, dynamic range, file size and fidelity. Two fundamental variables you should be aware of are sampling rate and bit depth (or resolution).
The sampling rate is the rate at which amplitude measurements are taken as an analog signal is converted or as a previously digitized file is resampled. The resampling process could downsample (which reduces the sampling rate) or upsample (which increases the rate).
Downsampling might be required when files recorded or created at higher sampling rates, such as 48 kHz (48,000 samples per second) or 96 kHz (48,000 samples per second) need to be prepared for audio CD distribution. This particular medium requires a sampling rate of 44.1 kHz (44,100 samples per second).
Upsampling is used by mastering engineers to create higher resolution files before processing to provide better results. This is followed by a downsampling process to prepare the file for distribution.
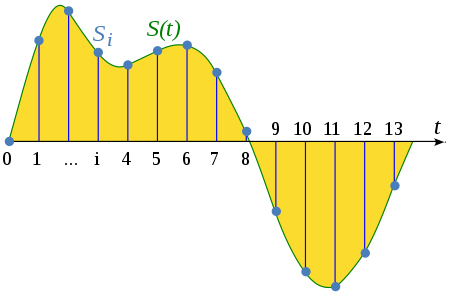
A visual representation of the sampling process.
(source)
Nyquist Rate
The Nyquist rate is a concept derived from digital sampling theory which states that to accurately represent a particular frequency, the signal must be sampled at twice the rate of that frequency. For example, to create an accurate digital representation of 10 kHz, you would need to use a minimum 20 kHz sampling rate. When the audio CD standard was developed this was one consideration in determining the standard sampling rate to be used. Based on the Nyquist theorem, a sampling rate of 44.1 kHz can accurately recreate a 22,050 Hz frequency in the digital realm. Since the range of human hearing is generally considered to be 20 Hz to 20 kHz, this was considered to be sufficient and manageable by computing systems and equipment at the time. Since then higher sampling rates have emerged as commonplace including 48 kHz (used in video contexts), 88.1 kHz, 96 kHz, and 192 kHz.
A logical question is — why use such high sampling rates when the limits of human perception stop after 20 kHz at the maximum. Part of the answer lies in the benefits of oversampling, which can reduce audio artifacts known as aliasing. When audio effects processing is performed at higher rates, the results are improved and the presence of artifacts is reduced. For more about oversampling check out my article: “Oversampling in Digital Audio: What Is It and When Should You Use It?”
In terms of recording, using higher sampling rates seems to provide a more pristine result as well. When interactions between frequencies occur, sum tones and difference tones are produced and the capability of a digital conversion process to represent frequencies beyond the range of human hearing can contribute to better results in the audible range.
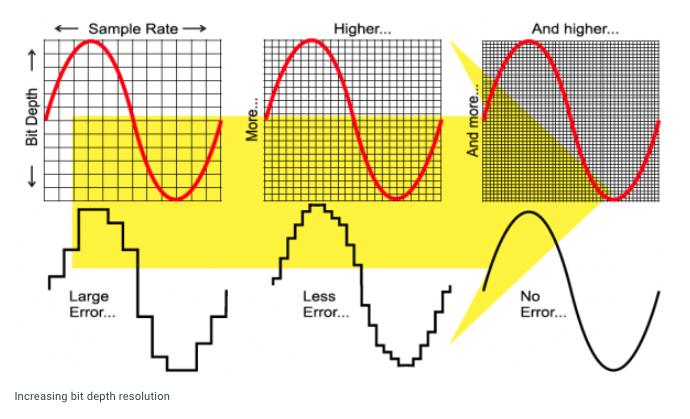
Equally or perhaps more important than sampling rate is bit depth or resolution. This can be thought of as the accuracy of how each sample is measured. The higher the bit depth the more accurate the amplitude measurement. The three most common bit depths used are 16, 24, and 32 bit. Referring back to the article mentioned above, “Bits, Bytes, and Beers,” each bit in a binary system can be either 0 or 1. This translates to a certain number of possible values based on the number of bits used. For example:
16 bit samples can have 216 possible values or 65,536
24 bit samples can have 224 possible values or 16,777,216
32 bit samples can have 232 possible values or 4,294,967,296
The higher the number of possible values the less quantization error and hence the less noise in a recording. This translates into a significantly wider dynamic range for 24 bit versus 16 bit recordings. (see the dynamic range chart above for the difference between a 16 bit and 24 bit audio).
Below is an example of two different bit depths used in computer graphics.
Consider two digital color palettes: 8 bit and 24 bit.


Note that in the 8 bit palette there are only 256 choices (28), meaning if you are trying to match an existing color, you can only get so close.
Ready to elevate your ears?
It doesn’t have to take years to train your ears.
Get started today — and you’ll be amazed at how quickly using Quiztones for just a few minutes a day will improve your mixes, recordings, and productions!
In the 24 bit palette, the choices are in the millions and the image appears to be almost a continuous blurring of one color transforming into the next. With this palette, you could get much closer to a specific color.
In terms of audio, less error or rounding of values means a more accurate digital representation of the analog input.
(source)
What Is Dithering and When to Use It?
It’s necessary or advisable to use a process known as dithering when a reduction of bit depth is required, such as when preparing a file produced in a 24 bit system for CD distribution, which requires a 16 bit file. Dithering helps to mitigate the quantization error that would normally occur in the process since by definition the digital accuracy is being reduced by lowering the bit depth. Dithering uses complex algorithms that counterintuitively introduce noise into the process to reduce unwanted artifacts. Because of this, you should never dither a file more than once and it should only be used when reducing bit depth.
What Is Lossy File Compression and What Are the Options?
The limitations of internet audio streaming and file size dictate the need for compression algorithms that can retain, as much as possible, the original quality of the sound file. You should be aware of two major categories of file compression formats — lossless and lossy.
Lossless audio file compression formats include:
FLAC (Free Lossless Audio Compression)
ALAC (Apple Lossless Audio Compression)
These files are made smaller for distribution but retain all the data from the original uncompressed file.
Lossy audio file compression formats include:
MP3 (MPEG layer 3)
AAC (Apple Audio Compression)
These files are made smaller for distribution by removing data based on the psychoacoustic limitations of human perception. When the algorithms identify certain audio content as being imperceptible at some defined degree, it removes that data, thereby reducing the file size. Once a file is compressed in this way, the original data is lost, unless a copy of the original is retained.
Uncompressed file formats include:
BWF (Broadcast Wave – supports metadata)
WAV (Waveform Audio File)
AIFF (Audio Interchange File Format)
These files can be transferred from place to place as exact copies of the original, but they are of course larger in size.
Lossy Compression and Data Rates
The user-defined data rate chosen for a file compression process will affect the resulting size and quality of the compressed file. Lower rates like 128 kbps (kilobits per second) and below will introduce unwanted artifacts in the resulting audio. 320 kbps is generally the highest bitrate for a compressed file that can be immediately streamed via the internet without having to download. To compare this to streaming a CD audio file, consider the required data rate of an uncompressed 44.1k/16 bit file:
44,100 x 16 = 705,600 x 2 (channels) = 1411200 bits = 1411 kbps
Final Thoughts
Capturing sound from the world and converting it into binary information lies at the heart of digital audio production. But what is missing from this description is the content created on the computer itself. Virtual instruments and soft synths are incredibly powerful creative devices that can produce astounding results with digital oscillators, wavetables, and the complete range of synthesis techniques once only available in hardware devices.
Whether you’re recording acoustic sources, generating sounds in the box or using digital effects, a basic understanding of how computers and other digital devices can be used to digest and manipulate sound is essential.
Check out my other articles, reviews and interviews
Follow me on Twitter / Instagram / YouTube
Eleveate Your Ears