4 Ways Vocals Are Different Than Any Other Signal in a Mix
02/25/2015
Article Content
In many styles of commercial music, the lead vocal is the most important signal in a song. As much as I love spending time mixing multitrack drums or tweaking guitar amps, there is no getting around the importance of a lead vocal. It’s more often than not the lead vocal that makes or breaks a song. Therefore, it’s worth taking particular care when working on vocals.
Besides just the importance of the vocal, it’s not always the easiest signal to work with. Conventional processing techniques for other instruments don’t always work well with vocals. This is because there are many ways a vocal is different from any other signal in your mix. Here are four that I came up with and how you can deal with them.
1. Alternates Between Periodic and Aperiodic
Some of the sounds that a vocalist produces are pitched (periodic), created when his/her vocal folds vibrate together. Other sounds are not pitched (aperiodic), created when air exits the singer’s lungs, but does not cause the vocal folds to vibrate.
Pitched sounds produce harmonics based on the fundamental frequency of the vibrating vocal folds. Examples of periodic sounds are vowels. Aperiodic vocal sounds do not have harmonics, and are similar to noise in some ways.
Examples of aperiodic sounds are some consonants, but not all. For instance, the syllable /fa/ is unvoiced, while /va/ is voiced. The main difference between these syllables is whether your vocal folds are vibrating. Otherwise, your mouth is in the same position.
There are many instruments common in mixes that are periodic signals or aperiodic signals. Piano, guitar, bass, horns, and strings primarily produce periodic signals. Percussive instruments primarily produce aperiodic signals (with some tone in a note’s sustain). There are no other common instruments like the voice that intermittently switch between periodic and aperiodic sounds.
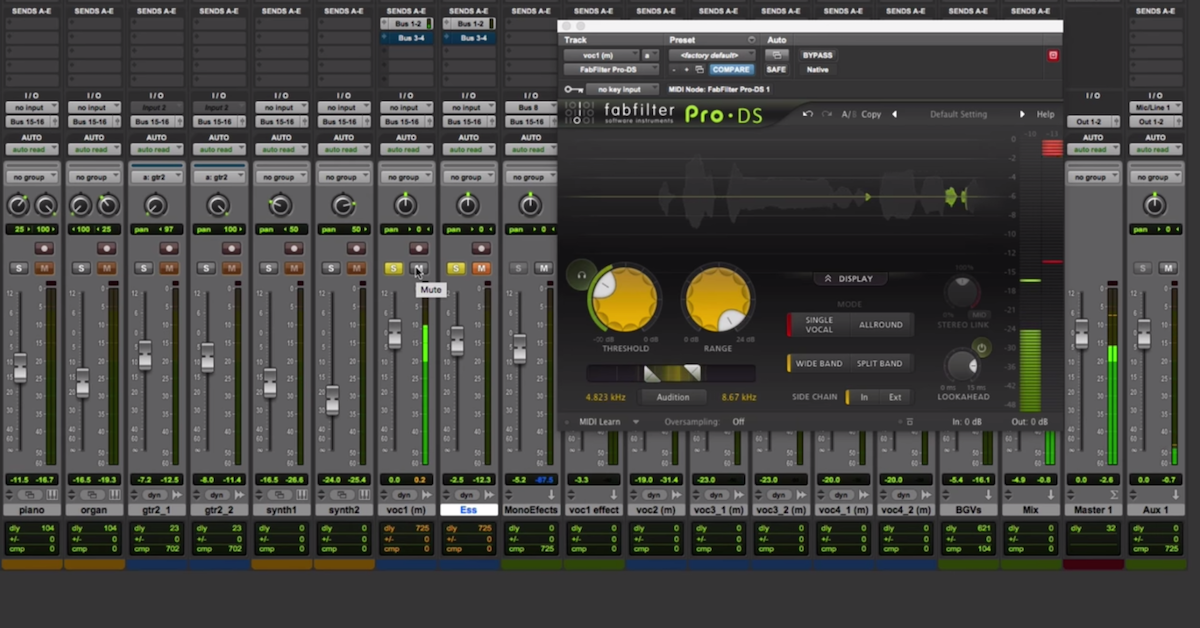
Periodic and aperiodic signals can be very different, and can sound very different. Therefore, it may be beneficial to process the two types of signals differently. The common way to process these types of signals is by using a de-esser. This processor is a special type of compressor that can be used to control the level of the high-frequency aperiodic signal separate from the low-frequency periodic signal.
Here are some techniques for controlling sibilance.
2. The Vocalist Has to Breathe
Not only do you have to worry about the periodic and aperiodic sounds of the notes that the singer produces, but you also have to worry about breathing between the notes.
All people playing instruments have to breathe, but the sound of the breath is rarely very loud compared to the instrument. By contrast, vocalists regularly breathe directly into a microphone during the recording of their performance. Each breath occurs before, between, or after the actual notes/words the vocalist is singing.
These breaths can be problematic if they’re too loud or too quiet in a mix. If the breaths are too loud, they can be distracting. If they’re too quiet, a vocal performance can sound unnatural because it sounds like the singer never breathes.
Depending on what you’re going for, you can also get creative with mixing the breaths.
3. ADSR Is Inconsistent, but Important
Many instruments produce a signal that has a consistent envelope.
A signal’s envelope can be characterized by attack, decay, sustain, and release.
A piano has a sharp attack at the start of a note and a long, quieter sustain by the end. A bass guitar can have more of a constant amplitude throughout a note with less decay. There are several instruments that can create a variety of different articulations like staccato, legato, pizzicato, etc.
Each type of articulation has different ADSR characteristics. When processing a signal it can be helpful to consider the ADSR characteristics for things like attack/release times on a compressor.
Ready to elevate your ears?
It doesn’t have to take years to train your ears.
Get started today — and you’ll be amazed at how quickly using Quiztones for just a few minutes a day will improve your mixes, recordings, and productions!
Not only can the human voice quickly switch between many different types of notes varying from staccato to legato, the ADSR characteristics are even more complicated than that. The ADSR also helps indicate the difference between certain syllables. For instance, the syllables /ba/ and /wa/ are very similar. One of the small differences between these sounds is the attack time. When a singer creates the /ba/ sound, their mouth opens very quickly. When a signer creates the /wa/ sound, their mouth opens relatively slowly. Otherwise, the sounds are created in a very similar way.
Because the vocal ADSR is inconsistent, but also very important, processing techniques (compression/expansion/etc) should definitely not screw it up.
Here are some resources for getting better at using compression.
4. Information is Carried in the Timbre
The relative amplitude of the harmonics in a signal is perceived as timbre.
This is one piece of information that helps listeners distinguish one type of instrument from another. The timbre also determines if an instrument sounds dull, bright, dark, muddy, harsh, etc.
The difference for the human voice is that the relative level of the harmonics actually carries the content of information in the signal. In fact, it’s the relative level of harmonics that distinguishes between different consonants and vowels.
During the production of the speech/singing signal, the sound begins when air exists the lungs and passes through the vocal box. Regardless of whether vocal folds are vibrating or not, the signal then passes through the vocal tract (consisting of the mouth and nasal cavity). The vocal tract acts as a resonating tube. Depending on the shape and configuration of the vocal tract, certain frequencies will resonate when they pass through the vocal tract. Other frequencies will be diminished when they pass through the vocal tract. Therefore, the relative level of harmonics changes when the speech/singing sound passes through the vocal tract.
Throughout a vocal performance, the shape of the vocal tract changes regularly. Therefore, the resonances that emphasize certain frequencies also change regularly. This is how different syllables and utterances are created. Another term used for a vocal spectral resonance is formant.
Because there is already a dynamic spectral envelope imposed on the signal from the vocal tract, special care should be taken when performing spectral processing on the voice. Adding a sharp spectral peak can actually create a formant that was not intended to be produced by the singer. Cutting with a sharp bell curve could remove some of the resonances produced by the singer. Your safest bet is to use broad peaking curves to enhance the resonances created by the singer. Additionally, a “tilt” style equalizer is a good way to make the overall sound brighter or darker when necessary.
Eleveate Your Ears