How to Back up Your Audio Projects
01/21/2022
Article Content
On March 18, 2020 at 7:00 in the morning — already on edge due to the COVID-19 lockdown that had sent me home from my teaching job just two days earlier, I was jolted awake by the Salt Lake City earthquake of 2020. It produced a tremendous rumbling sound (that was accompanied by a lot of breaking glass inside my house) and potent ground shaking. It had me wondering if this was an event I’d survive. Those of you who live near larger and more active fault lines may find this amusing, but this was my first time experiencing an earthquake, and I therefore had no point of reference to understand its severity. At moments of crisis like this one, of course it’s those close to us that truly matter. But in that moment I also thought about my data. Much of the work I’ve done as I have lived this life is documented in the form of digital data, including work I have done as a writer, music educator and music producer. I wondered how much of my work might be lost in this earthquake. Thankfully this quake resulted in no fatalities — only minor injuries. But it did cause nearly $630 million in property damage. I was lucky — my local data files remained intact and my particular residence escaped mostly unscathed, though many of my neighbors weren’t so lucky.
But, funny story, as I was preparing to write this article about data management nearly two years later, the main system solid state drive in my 4 month old computer failed for no apparent reason. I was glad that I had a recent disk image saved! More on that below.
What Can Cause Data Loss?
Distressingly, there are many potential causes of data loss. Some, like natural disasters, can be catastrophic, unpredictable and unavoidable. Others are due to human error, like this fictional scene in the TV Series Silicon Valley, where a character hanging out with the protagonists ended up deleting huge swaths of their partner company’s digital assets by absentmindedly pressing the delete key on a laptop with the corner of a tequila bottle — all while the team he financed frantically tried to troubleshoot the reason for data loss.
Sometimes portable drives get lost or damaged. Sometimes they simply stop working for reasons unknown. Power surges can fry circuitry. Water damage can occur from flooding or broken plumbing. Fires happen. Got any young children at home? If you do then you know what kind of property damage they’re capable of. Pets too. All of these things can cause data loss, and this isn’t even close to a complete list.
It’s important to understand that events that cause data loss are almost always unpredictable. In my 25 years of nearly daily computer use, I’ve dealt with three drive failures and one motherboard failure that took the attached drive with it. There was never any warning before these events. After losing valuable data once, I learned my lesson and now I make on-site disk image backups of my active drives every few weeks. I also keep copies of my most important files on cloud storage.
How to Protect Your Data as a DAW User
The concept is simple: make sure extra copies of your important files exist at all times in case one copy disappears for whatever reason. If you ever lose one of the copies, immediately make another copy and store it as safely as you can. But implementing this simple principle requires a well thought out, strategic plan and a disciplined execution of that plan to safeguard your important data. Deciding which files go into your presumably more limited cloud storage space and what does not is important. Having a plan for data restoration if you lose your working copies keeps downtime to a minimum. I’ll share my own data backup plan here in this article, but your own data situation probably differs. Finding time for thinking about how to manage your own data situation is encouraged.
What Gets Backed Up?
The choice of what data gets backed up is ultimately up to you and will vary based on your needs, type of work, available storage, etc.
First there’s your personal files. This would include things like your own photos, videos, financial data, music library, video library, etc. Since this article is mainly focused on data backups for DAW users I won’t go too deep here, but obviously these files need to be considered in your overall backup strategy.
If you’re a composer and/or performer producing original recordings, the absolute bare minimum for a data backup would include your mastered lossless audio/video files, along with any associated visual artwork — for example an album cover. These would be the files that you provide to your record label, publisher or digital distributor. If you ever need to redistribute your music or put your music on some kind of futuristic new media or platform, these are the files you’ll need. These audio files are typically going to be .wav or .aiff files, and they can be quite large — especially if you’re working with 24-32 bit audio at high sample rates like 96 kHz or 192 kHz & beyond. Some people choose to apply lossless audio compression codecs such as FLAC or Apple Lossless (ALAC) to these files before backing them up, and oftentimes you can save significant disk space with this compression technology — a 30-50% reduction in file size with no loss in audio quality is common. But be mindful of the specific codec you choose. Ask yourself if it’s likely to be supported in the future. If it ever becomes unsupported, you’ll need to convert your backups to a new format — sounds like a tedious chore to me. Others choose to simply back up the uncompressed PCM audio, but again this will consume some disk space.
If you’re working as an audio recording engineer then your backups will need to include entire DAW sessions, and this is what I recommend for all DAW users. More on that below.
Specific DAW Considerations
If you’re a composer/producer and you have the space & the resources, backing up your DAW projects (along with all of the media within) is a good idea. If you’re a recording engineer, full DAW session backups are mandatory. Imagine this scenario: you’re working with a valued client on a large scale project like an album. Tracking was great, mixing was flawless and you’re just about ready to send everything off to a mastering engineer… But then your audio drive fails and you lose everything because you didn’t take the time to make backups. Don’t put yourself in that situation. Professionals who value their clients make backups. To make backups of your potentially valuable DAW projects, several considerations must be made, especially if you work with a lot of virtual instrument and effects plugins.
Get into the habit of making a daily copy your work and save the copy to a separate drive. This will cover you if one of the drives were to fail. When a DAW-based project is completed I recommend archiving your work in two different forms, and again multiple copies are mandatory. First, it’s always a good idea to collect all of your project’s assets (such as audio & video files) and package them together with your DAW’s save file, along with any other auxiliary files (such as your notes) that your project may need to load successfully. This version of your archived project will contain everything you worked on, including MIDI data, track & mixer information, automation, audio files, virtual instruments, effects plugins… Literally everything you produced in the form of digital data. You may want to include installers for any plugins you used for especially valuable work, as these plugins may become unsupported in the future — companies sometimes go out of business and products are sometimes discontinued. Note the current versions of your operating system and DAW in case you ever need to restore the project, and save this information as part of your backup.
The other version that I recommend archiving is one where all tracks are printed to a new audio file. This includes all virtual instrument tracks, and all effects plugins get printed too. Any effect sends will likewise need to be printed to an audio track. The goal here is to create a DAW environment that sounds identical to your finished project, but only contains audio — no virtual instruments or effects plugins should be found here. Note that you’ll want to ensure that each and every audio file, regardless of its content, shares the same starting point at the beginning of the project. This will allow you to import these audio files into any DAW in the future. It’s also a good practice to adopt a file naming convention so you can find you way around your archives. You’ll want to include at least the name of the DAW project and the name of the track that contains the audio file. I personally like to include the date in the file name too. A good file naming convention can make it much easier to find what you’re looking for with your operating system’s file search tool.
The reason it’s important to have an audio-only version of your DAW projects is that oftentimes the plugins we use in our DAW projects become unsupported at some point. So if you need to open up a project that’s, say, 10 years old, you’ll probably be using a new computer with a newer operating system. Will those old plugins load? Sometimes, sometimes not. Even if you did the right thing and saved your plugin installers and activation directions, old installers can sometimes quit working on newer operating systems, so if/when a plugin becomes unsupported it simply can’t be relied on any more. But we can be relatively certain that PCM digital audio files will be supported far into the future. Even if your DAW were to become unsupported sometime down the line, you’ll always be able to load these audio files into a new DAW and make changes. It’s true that you won’t have the same editing abilities that you had with original MIDI tracks, but printed audio is often enough to make certain changes that your label or publisher requests, or that you want to make yourself.
The details of how to successfully back up your DAW projects varies from DAW to DAW, so take the time to learn all of these details for your particular DAW.
Practice Local Data Management With Backup Disk Images
Every time I finish a big project (or every few weeks, whichever comes first) I’ll back up each drive in my computer to an external hard drive. Each drive is saved as a disk image, which is a replica of all contents on the drive. The big advantage of working with disk images is that you have a drive failure, you can just remove the old broken drive from your system, insert a new one, and then copy the backup disk image over to the replacement disk. As long as the new drive is the same capacity or larger, data restoration is simple and easy. You’ll work with some kind of backup software to do this (see below).
Not all of my disks need to be backed up this often, and perhaps yours don’t either. For example, one SSD I use is dedicated to storing audio sample libraries, and that one only needs to be backed up when I add new content to it. It’s the main system drive (the one that contains your operating system and likely also contains your program files and plugins, but ideally not your audio recordings and samples) and any important work & personal files on your machine that are priorities for these disk image backups. Having a backup of the main system image recently saved me a lot of time and prevented a lot of headaches. You never know when an individual disk will call it quits. But we do know that each one will eventually — so it’s a matter of when, not if.
Apps for Local Disk Image Backups
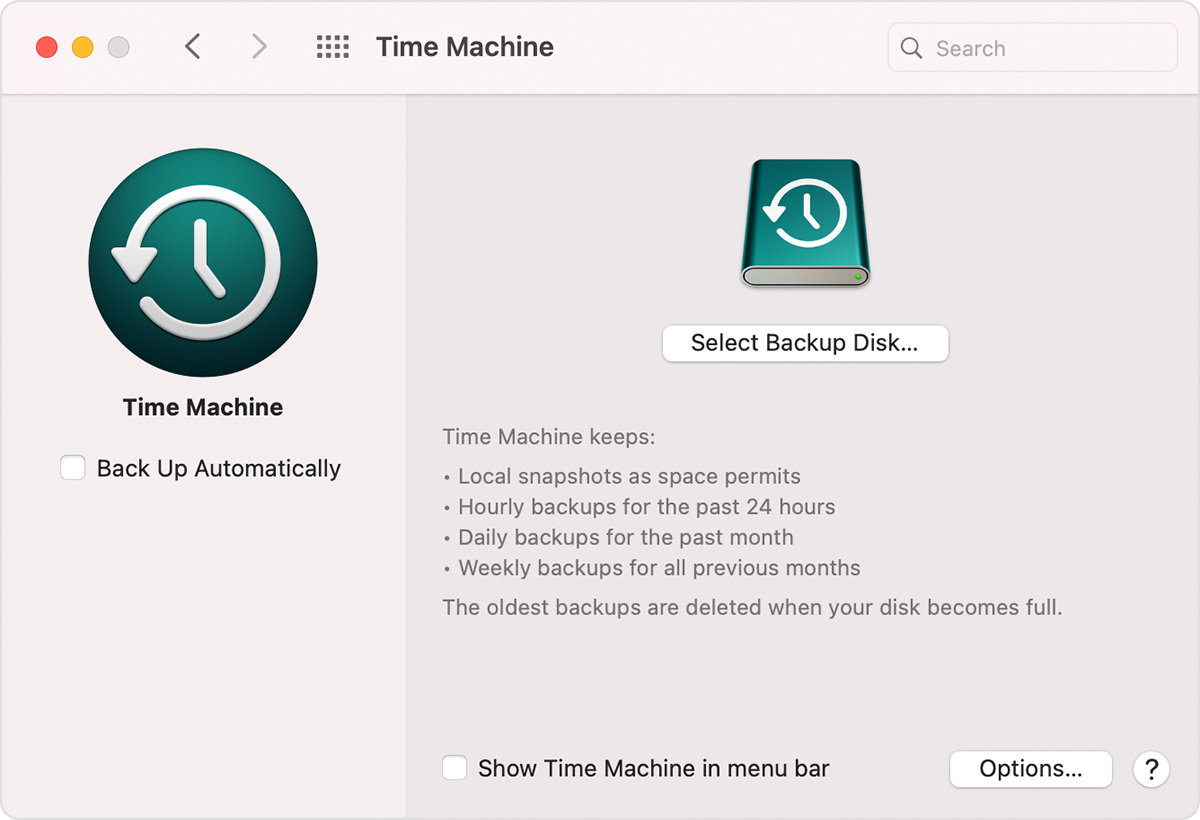
Mac Users: Time Machine
This is a simple, elegant solution. As long as you can find a disk with sufficient capacity to hold all of your data, using Time Machine is as easy as attaching that disk to your Mac and then making sure Time Machine runs and completes its tasks. Time Machine can even back up multiple disks to one backup disk. It’s exactly what I want out of a data management app. It’s thorough, it stays out of my way while working, and I doubt it’s possible to make something easier to use. It’s included in Mac operating systems, so sorry Windows users (and everyone else), Time Machine will only (legally) work for you on Apple’s expensive hardware.
Windows Users: Backup and Restore
While this software offers other options for backing up specific folders (which may be sufficient for more casual users), this Windows tool also allows full disk image backups. Restoration is built right into the OS and can also take place from a bootable recovery environment. This tool was originally introduced with Windows 7, but it’s also included in newer versions of Windows including 8, 10 and 11.
Macrium Reflect
This is an excellent free program (in most situations) that creates disk images quickly and easily. It also provides a custom bootable recovery environment. It’s solid and reliable.
Working With Cloud Storage as a DAW User
Cloud storage should be among the most reliable ways to back up your most valued data, but it’s not a guaranteed method. Nothing is perfect, but I do trust cloud storage with my most important professional and personal files. The big advantage that cloud storage provides is that if there was some sort of catastrophic event that wipes out all of your local data storage (something like a natural disaster) your data should remain intact since the data center(s) that store your files is/are likely to be geographically distant from your location.
Ready to elevate your ears?
It doesn’t have to take years to train your ears.
Get started today — and you’ll be amazed at how quickly using Quiztones for just a few minutes a day will improve your mixes, recordings, and productions!
I recommend backing up your most important personal files and archives of your DAW-based work to cloud storage. You don’t need to back up things like your operating system and most program files to the cloud, because if you ever need to reinstall those to a new machine you can usually just log into your user account and download a new installer from the software publisher.
Software for Cloud Backups
Splice Studio
This app is expressly designed to back up and sync DAW projects. This free service provides access to unlimited storage space, and it offers seamless integration for a variety of popular DAWs. It’s a solid platform for collaboration too; collaborators can upload changes to a shared project folder for others to download and respond to, and there’s a nice version control system built right in. I use Splice as a convenient redundant cloud storage service, as it’s phenomenal for saving working copies to the cloud. But I’m also careful to upload projects to my regular cloud-based archival space in Google Drive upon completion, due to section 5c of Splice’s Terms of Use document. Know what’s in that document if you use Splice Studio.
Other Cloud Storage Providers
There are many companies offering cloud storage services; way too many to cover in this article. Each of them are capable of providing cloud storage essentials; some offer features that may make life easier on you. Pick your service carefully and pay your bill on time. If you can’t pay, make sure you make copies of your cloud based files another way!
Take the Time
Data backup is a chore, I admit. But your work, your pictures, your videos and your cherished memories all deserve the attention. Professionally produced data is something that has the potential to be valuable, so protect the investment you made. Having good backups you can rely on can mean the difference between getting a nice payday or losing a client permanently.